




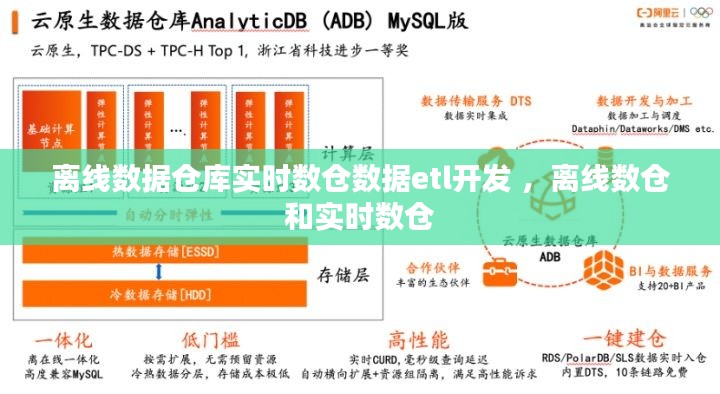
引言
随着大数据时代的到来,数据仓库在企业的数据分析中扮演着越来越重要的角色。传统的离线数据仓库在处理大量数据时效率较高,但响应速度较慢,无法满足实时决策的需求。为了解决这个问题,实时数仓应运而生。本文将探讨离线数据仓库与实时数仓的区别,以及如何进行离线数据仓库实时数仓的数据ETL(Extract, Transform, Load)开发。
离线数据仓库与实时数仓的区别
离线数据仓库通常在数据采集后进行批量处理,数据更新周期较长,如每日、每周或每月。这种模式适用于对数据准确性要求较高,但对实时性要求不高的场景。而实时数仓则能够实现数据的实时采集、处理和展示,适用于对数据实时性要求较高的场景,如金融风控、电商推荐等。
以下是离线数据仓库与实时数仓的主要区别:
- 数据更新频率:离线数据仓库更新周期较长,实时数仓更新频率高,通常为秒级或分钟级。
- 数据处理方式:离线数据仓库采用批量处理,实时数仓采用流处理或微批处理。
- 数据存储:离线数据仓库通常存储在传统的数据库或数据仓库中,实时数仓则可能使用NoSQL数据库或分布式存储系统。
- 应用场景:离线数据仓库适用于历史数据分析,实时数仓适用于实时决策支持。
离线数据仓库实时数仓的ETL开发
离线数据仓库实时数仓的ETL开发主要包括以下步骤:
1. 数据采集
数据采集是ETL的第一步,需要从各种数据源(如数据库、日志文件、API等)获取数据。对于实时数仓,数据采集通常采用流式数据处理技术,如Apache Kafka、Apache Flink等。
2. 数据清洗
数据清洗是确保数据质量的关键步骤。在实时数仓中,数据清洗通常包括以下内容:
- 去除重复数据
- 处理缺失值
- 数据格式转换
- 异常值处理
3. 数据转换
数据转换是根据业务需求对数据进行处理的过程,如计算、聚合、过滤等。在实时数仓中,数据转换通常采用流处理技术,如Apache Spark Streaming、Apache Flink等。

4. 数据加载
数据加载是将清洗和转换后的数据加载到目标数据存储系统中的过程。实时数仓的数据加载通常采用分布式存储系统,如Apache Hadoop HDFS、Amazon S3等。
技术选型与工具
在进行离线数据仓库实时数仓的ETL开发时,需要选择合适的技术和工具。以下是一些常见的技术和工具:
- 数据采集:Apache Kafka、Apache Flume、Logstash
- 数据清洗:Apache Spark、Apache Flink、Pig、Hive
- 数据转换:Apache Spark、Apache Flink、Pig、Hive
- 数据加载:Apache Hadoop HDFS、Amazon S3、Google Cloud Storage
- 数据存储:Apache Hadoop HDFS、Amazon S3、Google Cloud Storage、MongoDB、Cassandra
总结
离线数据仓库实时数仓的ETL开发是大数据时代企业数据管理的重要环节。通过实时数仓,企业可以实现数据的实时采集、处理和展示,从而满足实时决策的需求。本文介绍了离线数据仓库与实时数仓的区别,以及离线数据仓库实时数仓的ETL开发过程,希望对读者有所帮助。
转载请注明来自中维珠宝玉石鉴定,本文标题:《离线数据仓库实时数仓数据etl开发 ,离线数仓和实时数仓》




 豫ICP备17041525号-2
豫ICP备17041525号-2