




什么是实时分布式计算
实时分布式计算是一种计算模式,它允许系统在数据产生的同时进行处理和分析。这种计算模式在处理大量数据和高并发场景中尤为重要,如在线交易、社交网络分析、实时监控等。实时分布式计算的核心是能够快速、准确地处理数据流,并提供实时的反馈和决策支持。
实时分布式计算的关键技术
实现实时分布式计算需要依赖一系列的关键技术,以下是一些主要的技术组件:
分布式存储:如Hadoop的HDFS或Alluxio,它们能够提供高吞吐量和容错能力,支持大规模数据的存储。
分布式计算框架:如Apache Spark、Apache Flink等,这些框架能够高效地处理分布式数据,并提供流处理和批处理能力。
消息队列:如Apache Kafka,用于实现数据流的传输和缓冲,确保数据在分布式系统中的有序和可靠传输。
数据流处理:如Apache Flink或Apache Storm,它们能够实时处理数据流,提供低延迟和高吞吐量的处理能力。
实时分析引擎:如Apache Druid,用于实时查询和分析大规模数据集,提供实时的洞察和决策支持。
实时分布式计算架构设计
设计实时分布式计算系统时,需要考虑以下几个方面:
数据源集成:确保数据源能够高效地接入系统,包括日志、数据库、传感器数据等。
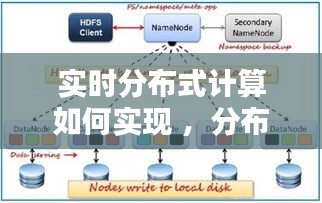
数据预处理:对数据进行清洗、转换和标准化,以便后续处理和分析。
数据处理逻辑:根据业务需求设计数据处理流程,包括数据流处理、批处理和实时查询。
数据存储和检索:选择合适的存储方案,如关系型数据库、NoSQL数据库或分布式文件系统。
系统监控和运维:实时监控系统性能,确保系统稳定运行,并及时处理故障。
实现实时分布式计算的步骤
以下是实现实时分布式计算的一些基本步骤:
需求分析:明确业务需求,确定实时数据处理的关键指标和性能要求。
系统设计:根据需求分析结果,设计系统的架构和组件,选择合适的分布式计算框架和存储方案。
数据集成:实现数据源与系统的集成,确保数据能够实时流入系统。
数据处理:编写数据处理逻辑,实现数据的预处理、流处理和批处理。
系统测试:对系统进行全面的测试,包括功能测试、性能测试和压力测试。
部署上线:将系统部署到生产环境,并进行监控和维护。
挑战与解决方案
实时分布式计算在实际应用中面临一些挑战,以下是一些常见的挑战和相应的解决方案:
数据一致性:在分布式系统中保证数据的一致性是一个挑战。解决方案包括使用分布式事务、一致性哈希等。
数据延迟:实时处理要求低延迟,解决方案包括优化数据处理逻辑、使用内存存储等。
系统可扩展性:随着数据量的增长,系统需要具备良好的可扩展性。解决方案包括水平扩展、分布式架构等。
故障恢复:系统需要能够快速从故障中恢复。解决方案包括数据备份、故障转移等。
总结
实时分布式计算是实现大数据实时处理和分析的关键技术。通过合理的设计和实施,实时分布式计算能够为企业和组织提供实时的业务洞察和决策支持。随着技术的不断进步,实时分布式计算将在更多领域得到应用,推动数据驱动的决策变得更加高效和精准。
转载请注明来自中维珠宝玉石鉴定,本文标题:《实时分布式计算如何实现 ,分布式shiro》








 豫ICP备17041525号-2
豫ICP备17041525号-2