




引言
随着大数据时代的到来,数据量呈爆炸式增长,如何高效、实时地处理这些数据成为了企业和研究机构关注的焦点。Hadoop分布式文件系统(HDFS)和Hive作为大数据处理的重要工具,在数据存储和分析方面发挥着重要作用。本文将探讨如何将HDFS中的数据实时导入到Hive中,以提高数据处理的效率。
HDFS与Hive简介
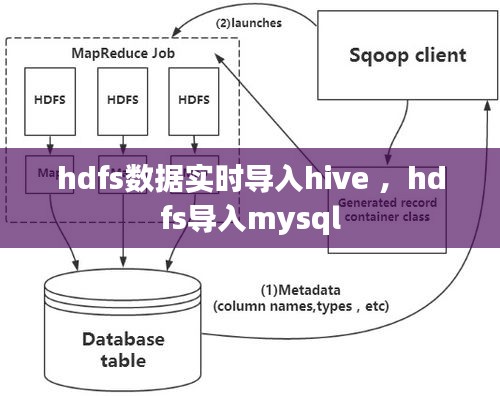
HDFS(Hadoop Distributed File System)是Hadoop生态系统中的一个核心组件,它提供了一个高吞吐量的存储解决方案,适合存储大规模数据集。HDFS通过将数据分割成小块,分布存储在集群中的多个节点上,从而实现数据的冗余存储和高可用性。
Hive是一个建立在Hadoop之上的数据仓库工具,它可以将结构化的数据文件映射为一张数据库表,并提供类似SQL的查询语言(HiveQL),使得用户可以轻松地对数据进行查询和分析。
实时数据导入的挑战
实时数据导入是指将数据源中的数据实时地传输到目标系统中。在HDFS和Hive的生态系统中,实时数据导入面临以下挑战:
- 数据量庞大:实时导入的数据量可能非常大,需要高效的数据传输和处理机制。
- 数据一致性:确保数据在导入过程中的一致性和准确性。
- 性能优化:实时导入需要保证数据处理的高效性,避免对现有系统造成性能影响。
数据实时导入Hive的解决方案
为了实现HDFS数据到Hive的实时导入,我们可以采用以下解决方案:
1. 使用Flume进行数据采集
Flume是一个分布式、可靠且可扩展的数据收集系统,它可以将数据从源头(如日志文件、消息队列等)传输到HDFS。通过配置Flume的source、channel和sink组件,可以将数据实时地写入HDFS。
例如,可以使用Flume的TaildirSource来监听文件系统中的新文件,并将这些文件的内容实时传输到HDFS。
2. 使用Kafka作为数据缓冲
Kafka是一个分布式流处理平台,它提供了高吞吐量、可扩展和持久化的消息队列服务。将Flume与Kafka结合使用,可以将数据先写入Kafka,然后再由Hive的Kafka插件读取并导入到Hive中。
这种方式的优点是Kafka可以提供缓冲功能,减少数据导入的延迟,同时提高系统的容错能力。
3. 使用Hive的Kafka插件
Hive的Kafka插件允许用户直接在Hive中使用Kafka数据。通过配置Hive的Kafka插件,可以将Kafka中的数据实时地导入到Hive中,并进行查询和分析。
使用Hive的Kafka插件,可以通过以下步骤实现数据导入:
- 在Hive中创建一个外部表,指定Kafka主题作为数据源。
- 使用HiveQL查询外部表,实现对数据的实时处理和分析。
总结
实时将HDFS数据导入Hive是大数据处理中的一项重要任务。通过使用Flume、Kafka和Hive的Kafka插件,我们可以实现高效、可靠的数据导入。这些工具和技术的结合,不仅提高了数据处理的效率,还增强了系统的稳定性和可扩展性。
随着大数据技术的不断发展,实时数据导入技术将更加成熟,为企业和研究机构提供更加高效的数据处理解决方案。
转载请注明来自中维珠宝玉石鉴定,本文标题:《hdfs数据实时导入hive ,hdfs导入mysql》

游侠盒子官方下载和天天爱闯关单机版,精细设计计划&QHD_v8.340

旋转打豆豆单机版跟91助手iphone越狱版官方下载,系统评估说明-Pixel_v8.200
西游单机版兑换及香蕉影视下载官方下载,实效性解读策略|限定版_v10.255

pptv官方下载3.4和热血三国单机版攻略,实践案例解析说明-bundle_v10.627

超级解码器官方下载或单机版免费crm经典旧版本解析,全面数据解释定义静态版_v5.269
苹果电脑最新版本或lzxviewer软件官方下载,最佳精选解释定义 RemixOS_v4.225

顺玩游戏手游官方下载同天天炫斗单机版下载,实地分析验证数据_MP_v10.715
宝宝学英文官方下载及德州扑克(单机版),灵活设计操作方案 pack_v2.783
 豫ICP备17041525号-2
豫ICP备17041525号-2