




引言
随着互联网的飞速发展,数据已经成为企业和社会的重要资产。在众多数据中,热门话题和数据往往能够反映出社会趋势和用户兴趣。Python作为一种功能强大的编程语言,在数据采集和分析领域有着广泛的应用。本文将探讨如何使用Python进行热门话题的采集,帮助读者了解这一领域的最新动态。
Python数据采集概述
Python数据采集主要依赖于以下几个库:requests、BeautifulSoup、Scrapy等。这些库可以帮助开发者轻松地从网页中获取数据。以下是这些库的基本介绍:

- requests:这是一个简单的HTTP库,用于发送HTTP请求,获取网页内容。
- BeautifulSoup:这是一个用于解析HTML和XML文档的库,能够方便地从网页中提取所需数据。
- Scrapy:这是一个强大的网络爬虫框架,可以高效地从一个或多个网站中抓取数据。
热门话题采集方法
要采集热门话题,首先需要确定采集的目标。以下是一些常见的热门话题采集方法:
1. 社交媒体采集
社交媒体平台如微博、知乎、豆瓣等,是热门话题的重要来源。以下是一个简单的Python代码示例,用于从微博采集热门话题:
import requests
from bs4 import BeautifulSoup
def get_weibo_hot():
url = 'https://s.weibo.com/top/summary'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
hot_topics = soup.find_all('tr')
for topic in hot_topics:
rank = topic.find('td', class_='td-01').text.strip()
title = topic.find('td', class_='td-02').a.text.strip()
print(f'排名:{rank},标题:{title}')
if __name__ == '__main__':
get_weibo_hot()
2. 新闻网站采集
新闻网站是另一个热门话题的重要来源。以下是一个简单的Python代码示例,用于从新浪新闻采集热门话题:
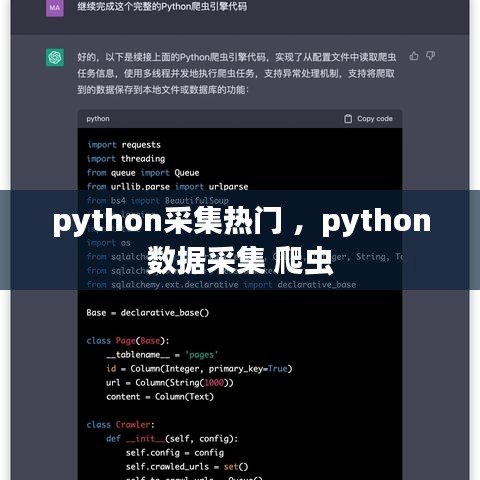
import requests
from bs4 import BeautifulSoup
def get_sina_news_hot():
url = 'https://news.sina.com.cn/hotnews/'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
hot_topics = soup.find_all('a', class_='list_title')
for topic in hot_topics:
title = topic.text.strip()
print(f'标题:{title}')
if __name__ == '__main__':
get_sina_news_hot()
3. 搜索引擎采集
搜索引擎如百度、谷歌等,也可以作为热门话题的采集来源。以下是一个简单的Python代码示例,用于从百度搜索采集热门话题:
import requests
from bs4 import BeautifulSoup
def get_baidu_hot():
url = 'https://www.baidu.com/s?wd=hot'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
hot_topics = soup.find_all('a', class_='c-abstract')
for topic in hot_topics:
title = topic.text.strip()
print(f'标题:{title}')
if __name__ == '__main__':
get_baidu_hot()
总结
Python作为一种强大的编程语言,在数据采集和分析领域有着广泛的应用。通过使用requests、BeautifulSoup、Scrapy等库,我们可以轻松地采集热门话题数据。本文介绍了几种常见的热门话题采集方法,包括社交媒体、新闻网站和搜索引擎。希望这些方法能够帮助读者更好地了解热门话题,为数据分析提供有力支持。
转载请注明来自中维珠宝玉石鉴定,本文标题:《python采集热门 ,python数据采集 爬虫》




 豫ICP备17041525号-2
豫ICP备17041525号-2